
NVIDIA Research Says Small Language Models Will Power the Next Wave of Agentic AI

NVIDIA’s latest research argues that many AI agents work better when they use fleets of small, fast models that run close to you, not just one giant model in the cloud.
But does the shift really matter, and does that mean frontier models like GPT-5, Perplexity and Claude won’t make it into the future? Not exactly.
TLDR
- NVIDIA’s researchers contend that small language models (SLMs) are now strong enough for many agent jobs. They’re like nimble scooters weaving through city traffic while tour buses sit at red lights.
- SLMs run locally or on modest servers with low latency and cost, and they are easy to fine‑tune for narrow jobs like pulling data into JSON or calling an API.
- Keep a larger model on standby for open‑ended conversations and messy, novel problems.
Primer On Agents And Models
An AI agent is software that does things on your behalf. It reads an instruction, decides which tools to use, performs steps, and returns results. Picture a helpful assistant who knows where the forms are, who to call, and how to file things in the right folder.
A language model is the brain that helps the agent understand instructions and format responses. Large models are like encyclopedias with a chatty personality. Small models are like pocket guides that focus on the job at hand.
What Counts As “Small” Today
In the NVIDIA paper, an SLM is a model that fits on a common consumer device and responds quickly for a single user. As of 2025, that usually means under about 10 billion parameters.
The number will shift over time, the way phone storage once felt huge at 16 GB and now feels tiny.
Why Agents Often Work Better With Small Models
Most real agent tasks are repetitive, scoped, and structured. They parse emails, draft tickets, fill forms, call APIs, and format outputs. A specialist that nails these patterns is like a barista who remembers your order and gets it right without small talk.
Key advantages you feel immediately:
- Snappy responses: Fewer parameters means less to compute, which shortens wait time.
- Lower costs: Inference bills drop because you are not pushing a freight train for a bicycle trip.
- Easier tuning: You can tweak a small model for your workflow with modest data and time.
- Better privacy options: Running locally keeps sensitive data close to home.
Where Big Models Still Shine
Keep a larger model available for broad conversation, ambiguous requests, and novel reasoning.
When the path is unclear, a generalist can brainstorm, then hand off concrete steps to the specialists.
It is like calling a chef to plan a menu, then letting line cooks execute the recipes.
The SLM‑First Architecture
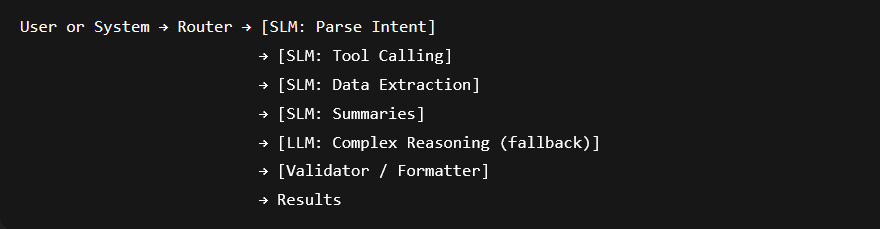
- Router: Decides which model gets the task.
- Specialist SLMs: Fast executors for common, narrow steps.
- LLM Fallback: Strategic helper for hard or fuzzy problems.
- Validator: Ensures outputs match the format your code expects.
The router is the expediter, SLMs are stations, the big model is the head chef who steps in when a new dish comes in.
Evidence From The Research
The paper’s position rests on three pillars:
- Capability: Modern SLMs handle commonsense tasks, tool use, and instruction following well enough for many agent workflows.
- Fit: Agent steps demand strict formats and predictable behavior, which aligns with specialists.
- Economy: A 7B SLM can be an order of magnitude or more cheaper to serve per request than a much larger model, with fewer headaches around scaling.
The authors even outline conversions in popular open‑source agents, estimating that 40 to 70 percent of current large‑model calls could be replaced by SLMs after targeted tuning.
A Migration Plan You Can Run This Quarter
You do not need a moonshot. Start small, then expand.
- Capture prompts, tool invocations, and outputs for non‑chat tasks. Add latency metrics. You are building a map, not a novel.
- Remove sensitive data and normalize formats. A tidy pantry makes faster dinners.
- Group similar tasks: intent parsing, tool calling, data extraction, summarization, code fixes. The clusters reveal which specialists to train first.
- Choose models sized for your hardware and task types. Check context window, instruction‑following quality, license, and memory footprint.
- Use your clustered data to teach each SLM a tight job. Parameter‑efficient techniques keep compute needs manageable.
- Route simple and structured tasks to SLMs. Send tricky items to a larger model. Track accuracy and latency, then refine your data and prompts. Improvement loops are your flywheel.
What You Can Replace First
Based on the paper’s case studies and common patterns, these are prime candidates:
- Function and API Calling with strict schemas
- Document Extraction into fields for invoices, claims, and tickets
- Template‑Bound Summaries like daily briefs and status updates
- Light Coding Steps such as boilerplate generation or quick fixes
Each success reduces load on your large model.
Barriers You Will Face And How To Clear Them
Metaphorically, you are shifting from one heavy Swiss Army knife to a drawer of sharp, single‑purpose tools.
- Existing commitments to big‑model infrastructure: Start with a pilot alongside your current stack. Let numbers speak.
- Benchmarks that favor generalists: Track the metrics that matter to your workflow, such as schema compliance and time to first token.
- Awareness and habit: Share internal demos where SLMs feel instant. People believe what they can see and touch.
The Economic Stakes Of The Shift
The LLM-centric way of building agents has a hidden bill attached. Running a single giant model in the cloud requires massive infrastructure, and the numbers no longer add up cleanly.
In 2024 alone, companies poured around $57 billion into datacenters to serve LLM APIs, while the actual market for those APIs was only worth about $5.6 billion. That’s a ten-to-one imbalance.
You’re Not Paying The Actual Cost Of AI APIs
When you call an AI API today, you see a tidy price per thousand tokens. What you don’t see is the sprawling infrastructure humming behind it. Data centers packed with high-end GPUs, energy bills that rival small cities, and engineering teams keeping the whole system upright.
Those hidden costs are absorbed by the vendors and their investors. The $0.003 per token you pay is heavily subsidized, a bet that scale will eventually balance the books. But the economics are shaky.
As NVIDIA’s researchers point out, the spend on cloud hardware has outpaced revenue by a wide margin. In effect, you’re riding on a loss leader.
Why Does That Matter?
Every time an agent uses a large model to format a JSON snippet or make a routine API call, you are paying for thousands of unused neurons to sit idle.
Small language models change the math. A 7-billion-parameter model can be 10 to 30 times cheaper to run per request. They also cut power consumption and remove the need for sprawling multi-GPU clusters just to keep latency tolerable.
For enterprises, that means scaling agents without scaling costs. For smaller teams, it means deploying capable AI without waiting for cloud credits or massive funding rounds.
Conclusion
NVIDIA’s research makes the case that the future of agentic AI is not about who can build the biggest model, but who can build the smartest system. Small language models give you speed, the ability to run closer to where the work happens.
Large models still matter, but they will become the occasional specialists rather than the everyday engines. The AI market is moving from a race for scale to a race for efficiency. Those who adapt early will be the ones who win when the subsidies fade and the real costs surface.
FAQs
What is a Small Language Model (SLM)?
A small language model is a compact AI system, usually under 10 billion parameters, that can run locally or on modest servers. They deliver fast, low-cost responses and are well suited for repetitive, structured agent tasks.
How are SLMs different from LLMs like GPT-5 or Claude?
LLMs are generalists designed for open-ended conversation and complex reasoning. SLMs are specialists that excel at narrow, predictable jobs such as parsing data, calling APIs, or generating structured outputs.
Why would I use an SLM instead of an LLM?
SLMs cost much less to run, respond faster, and can often be fine-tuned overnight for your specific workflow. They also allow on-device deployment, giving you stronger privacy and independence from cloud APIs.
Will large language models disappear?
No. LLMs will remain important for broad reasoning and ambiguous problems. The future is hybrid: fleets of small models handle most tasks, while a large model steps in only when necessary.
What tasks can I replace with SLMs right now?
Good candidates include function calling, document extraction, template-based summaries, and routine code generation. These account for a large share of real agent workloads.
Are AI API prices sustainable?
Current AI API prices are heavily subsidized by massive infrastructure investment. As subsidies decline, costs are likely to rise. Using SLMs now protects you from that correction and keeps your AI budgets predictable.

